KH-Coder連携篇
【GPT_Textminingシリーズ一覧リンク】
- 第1回 入門編・グーグルスプレッド&API
- 第2回 グーグルスプレッド・サマライズ等
- 第3回 通常の対話型インターフェイスを使った単語抽出など
- 第4回 マイニングツールKH-Coderとの連携について
- 第5回 ワードクラウドを表示するHTMLを作る
- 第6回 エクセルをそのままコードインタープリターで加工する
【はじめに】
今回は調査分析の実戦を想定した話をします。第3回の対話篇では、ChatGPTの対話画面から、100行以上のテキストデータを記憶し、そこから抽出した単語をグルーピングしてカウントするという方法をご紹介しました。
しかし実際の調査では、1000人2000人の回答を分析することは珍しくなく、このままではあまり実用的ではありません。そこで、恐らく日本で最も使われているテキストマイニングツールと思われる「KH Coder」との連携ができないか試してみました。そのため、今回の投稿は「KH Coder」と、「自由文回答のアフターコーディング」について多少の見識を持った人を対象に書いています。ご了承下さい。
※「KH Coder」は計量テキスト分析またはテキストマイニングのためのフリーソフトウェアです。 (リンクはコチラ)
【事前準備事項】
KH Coderをダウンロードしインストールしてあること。ChatGPTの対話画面。
【必要スキル】
KH Coderの基本的な操作ができること。本シリーズの第3回の内容を理解できていること。
【動画】
作業の全体の流れ
- まずは、KH-Coderにデータを読み込み、前処理を行います。この段階で、単語の出現回数などは数えられています。(KH-Coderのダウンロードとインストール、分析用のファイル(エクセルやCSV)の作り方、前処理の仕方などは、上記のリンクを参考にしてください)
- 次に、アフターコーディングという作業をして、選択肢型の質問のようにクロス集計を行います。この際に、コーディングルールという表を作成する必要があります。この表は人間が作る必要がありますが、
- 分類的にも、記述するにも面倒な作業になります。そこで、GPTにやってもらおうというわけです。
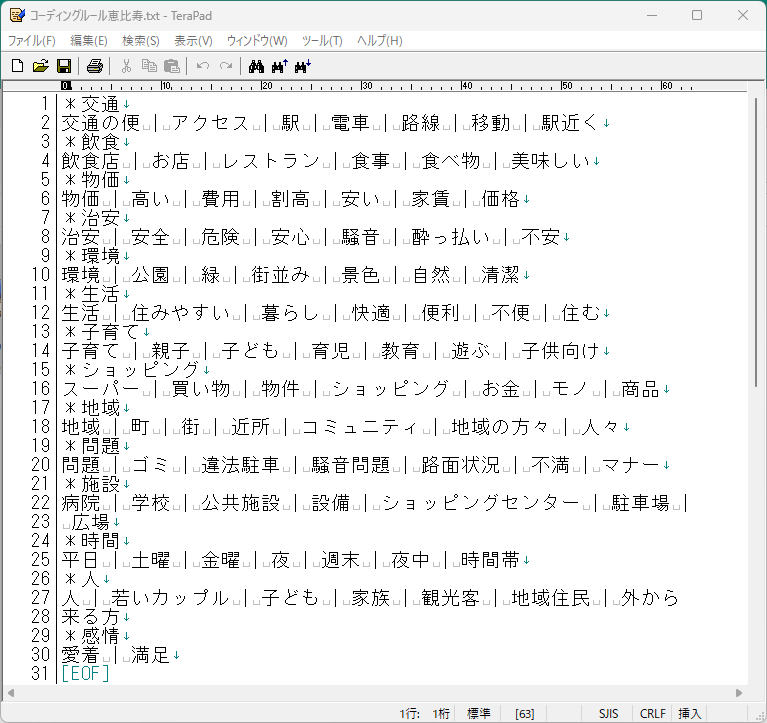
■KH-Coder用のコーディングルール例 *以下にキーワード 改行後に該当する単語を | で区切ることになっている。
- 最後にKH-Coderに戻って、クロス集計を行います。
GhatGPTでの作業
ChatGPTの対話画面を使い作業をします。
前回(第3回)にご紹介した、分析用の自由回答文を複数回に分けてChatGPTに記憶してもらう方法を使って記憶させ、その後にひとつに統合します。動画では”分析用テキスト全て”と名前をつけています。(前回と同じ”恵比寿の街についてのアンケート”を例に使っています)

■前回紹介した100行以上のテキストをChatGPTに記憶させる方法の一部
- 次に、約120行分のテキストが記憶された”分析用テキスト全て”について、形態素解析後に単語を抽出し、似た意味の単語を15個にグループ化して、グループ名を付けてKH-Coderのコーディング形式で表示するように指示します。
プロンプト
[ ”分析用テキスト全て”について、形態素解析を行い、単語を抽出して、似た意味の単語を15個にグループ化して、グループ名を付けて次の形式で表示してください。*”グループ名”改行”単語1″” | “”単語2″” | “単語3″…… ]
今回のGPTでの作業はこれだけです。
その後、KH コーダーにコーディングルールをコピペして、必要であれば形を整えます。ChatGPTは同じプロンプトを使っても違う挙動を示すことがあります。今回の下準備でも、グルーピング内容は同じでも、出力形式が間違っていたり……アスタリスクが半角になっていたり、ダブルクォーテーションが付いたり付かなかったりしました。このあたりは、ChatGPTにやり直し「指定した形式になっていません」をさせたり、テキストエディタの置き換えなどで修正してください。
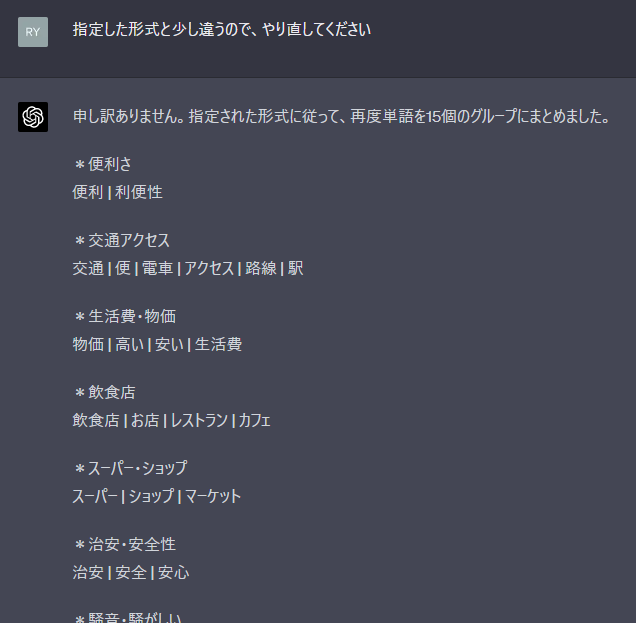
■プロプトを実行させた後、*なしで出力してきたのでやり直ししてもらった画面。まだ余分な改行が入っている
この結果をテキストエディタから名前を付けて(恵比寿アンケートコーディングルール.txtなど)保存します。KH-Coder用のコーディングルールが完成しました。
KH-Coderでの作業
今回は、KH-Coderで分析するデータも、ChatGPTでコーディングルールを作るために使用したデータも同じ内容ですが、実戦では、例えば3000行のデータのうち、最初の150行をChatGPTで使うことを想定しています。この150行で”コーディングルール”を作成し、その後に3000行のデータに対してKH-Coderでクロス集計を行うわけです。
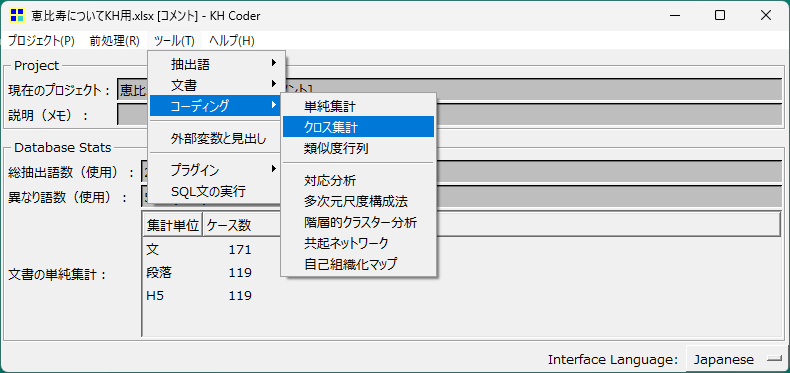
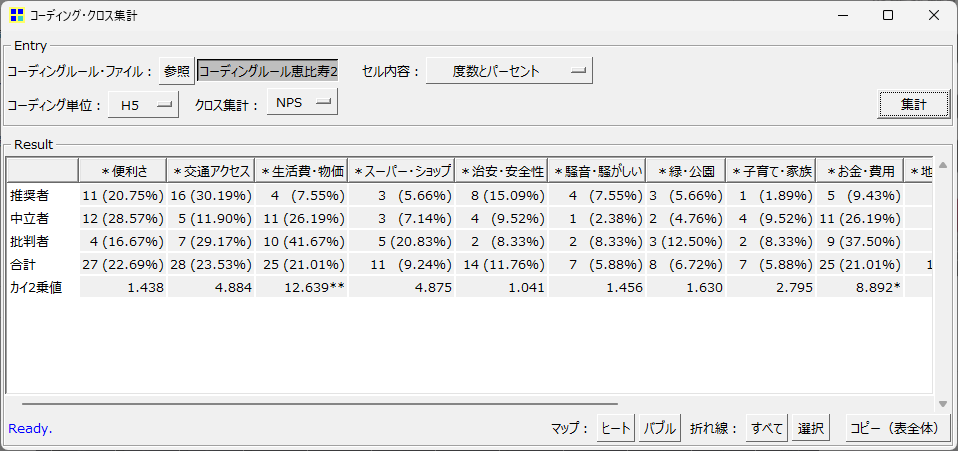
KH-Coderでの実際の作業は簡単です。[ツール]→[コーディング]→[クロス集計]を選び、コーディングルール・ファイルで先ほど作成したルールファイルを指定、クロス属性や出力形式を選択して[集計]をクリックします。以下のようなクロス集計表が出来上がります。
【あとがき】
今回はアンケート集計・分析を専門にしている人を対象にした内容になっていますが、ChatGPはそのような専門家の作業を軽減させる可能性も持っているようです。
【ChatGPTテキストマイニングシリーズ一覧リンク】
ChatGPTをグーグルスプレッドのアドオンで関数のように使って文のネガポジ分析を行う
アンケート自由記述回答をChatGPTでカテゴリー分類しサマライズする方法
ChatGPTのチャットインターフェイスを使って文章からキーワードの抽出と出現回数を調べる
ChatGPTでKH-Coder用のコーディングルール自動作成する方法
ChatGPTにプロンプトをチャットするだけでワードクラウドを作る方法
Advanced Data Analysis (旧名・コードインタープリター)でエクセル上のアンケートデータにフラグアップなど複数の作業をまとめて行う
ExcelとChatGPTを使った実用的で高精度なアンケート自由記述回答分析の最新技法を紹介
【著者・author】
吉澤 隆(よしざわ りゅう)
株式会社マーケティングジャンクション代表取締役
1997年、日本で最初のネットリサーチ会社”マーケティングジャンクションを”を設立。2002年2月、ネットリサーチ系スタートアップ企業が寄り集まって、インターネットリサーチ研究会を立ち上げ活動を開始し、2003年の3月には、6社のツールベンダーとサービス提供会社、300人の参加者があつまり「テキストマイニングセミナー」を開催。以来、アンケート調査の自由記述回答に関するテキストマイニングサービスを提供。2023年3月より誰もが利用できる自由文分析方法として、ChatGPTテキストマイニングの研究・普及活動を展開。当ホームページ、Youtube、他社ホームページ向けの寄稿を行っている。

【新サービスのお知らせ】リサーチ&コンテンツ[詳細はこちら]
BtoB WEBページのPR集客とコンバージョンを引き上げる総合サービスメニューです。ターゲット設定、全体企画、調査実施、分析コンテンツ、プレスリリース、ダウンロード用白書制作まで。特設ページで詳しくご案内しています。


